Das moderne Zeitalter des KI-Trainings, insbesondere für große Modelle, sieht sich sowohl mit Anforderungen hinsichtlich Rechenleistung und striktem Datenschutz konfrontiert. Traditionelles maschinelles Lernen (ML) erfordert eine Zentralisierung der Trainingsdaten, was zu erheblichen Hürden und Aufwand in Bezug auf Datenschutz, Sicherheit und Dateneffizienz/-volumen führt.
Diese Herausforderung wird in heterogenen globalen Infrastrukturen in Multicloud-, Hybrid Cloud- und Edge-Umgebungen noch größer. Daher müssen Unternehmen Modelle mithilfe der vorhandenen verteilten Datensätze trainieren und gleichzeitig den Datenschutz wahren.
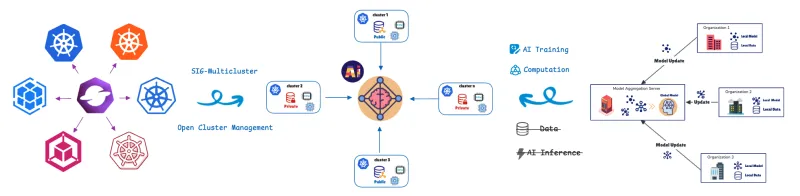
Föderiertes Lernen (FL) löst dieses Problem, indem das Modelltraining in die Daten verlagert wird. Remote-Cluster oder -Geräte (Mitwirkende/Clients) trainieren Modelle lokal mit ihren privaten Daten und geben nur Modellaktualisierungen (nicht die Rohdaten) an einen zentralen Server (Aggregator) weiter. Dies trägt zu einem umfassenden Datenschutz bei. Dieser Ansatz ist entscheidend für datenschutzkonforme Szenarien oder Szenarien mit hoher Datenlast, die wir im Gesundheitswesen, im Einzelhandel, in der industriellen Automatisierung und bei softwaredefinierten Fahrzeugen (SDV) mit fortschrittlichen Fahrerassistenzsystemen (ADAS) und Funktionen für autonomes Fahren (AD) wie Fahrspurhalteassistent, adaptive Geschwindigkeitsregelung und Überwachung der Fahrerermüdung finden.
Zum Verwalten und Orchestrieren dieser verteilten Recheneinheiten verwenden wir die benutzerdefinierte Ressourcendefinition (CRD) für föderiertes Lernen von Open Cluster Management (OCM).
OCM: Die Basis für verteilte Operationen
OCM ist eine Kubernetes-Plattform für Multicluster-Orchestrierung und ein Open Source CNCF-Sandbox-Projekt.
OCM verwendet eine Hub-Spoke-Architektur und nutzt ein Pull-basiertes Modell.
- Hub-Cluster: Dieser Cluster dient als zentrale Steuerungsebene (OCM Control Plane), die für die Orchestrierung verantwortlich ist.
- Gemanagte (Spoke-)Cluster: Dies sind Remote-Cluster, in denen Workloads bereitgestellt werden.
Gemanagte Cluster rufen ihren gewünschten Zustand ab und melden den Status zurück an den Hub. OCM bietet APIs wie ManifestWork und Placement zur Planung von Workloads. Im Folgenden werden weitere Details zu den APIs für föderiertes Lernen behandelt.
Sehen wir uns an, warum und wie das verteilte Clustermanagement-Design von OCM den Anforderungen der Bereitstellung und Verwaltung von FL-Mitwirkenden entspricht.
Native Integration: OCM als FL-Orchestrator
1. Architekturausrichtung
Die Kombination von OCM und FL ist aufgrund ihrer grundlegenden strukturellen Übereinstimmung effektiv. OCM unterstützt FL auf native Weise, da beide Systeme ein identisches grundlegendes Design aufweisen: die Hub-Spoke-Architektur und ein Pull-basiertes Protokoll.
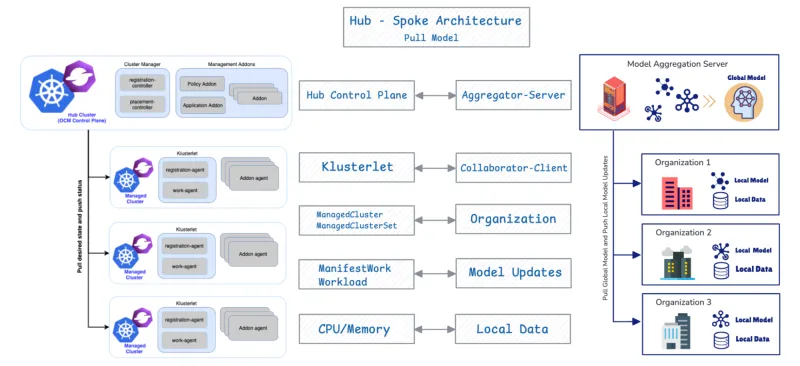
OCM-Komponente | FL-Komponente | Funktion |
OCM Hub Control Plane | Aggregator/Server | Orchestriert zustandsbezogene und aggregierte Modellaktualisierungen. |
Gemanagter Cluster | Mitwirkende/Client | Ruft den gewünschten Zustand/das globale Modell ab, trainiert lokal und überträgt Aktualisierungen. |
2. Flexible Platzierung für die Auswahl mehrerer Akteure beim Client
Der wichtigste operative Vorteil von OCM ist die Fähigkeit, die Clientauswahl in FL-Setups durch Nutzung der flexiblen, clusterübergreifenden Planungsfunktionen zu automatisieren. Diese Funktion verwendet die OCM Placement API, um ausgefeilte Richtlinien mit mehreren Kriterien zu implementieren und so Effizienz und gleichzeitige Datenschutz-Compliance zu gewährleisten.
Die Placement API ermöglicht eine integrierte Clientauswahl auf Grundlage der folgenden Faktoren:
- Datenlokalität (Datenschutzkriterium): FL-Workloads werden nur für verwaltete Cluster geplant, die angeben, über die erforderlichen vertraulichen Daten zu verfügen.
- Ressourcenoptimierung (Effizienzkriterium): Die OCM-Planungsstrategie bietet flexible Richtlinien, die die kombinierte Bewertung mehrerer Faktoren ermöglichen. Die Lösung wählt Cluster nicht nur nach dem Vorhandensein von Daten, sondern auch nach angebotenen Attributen wie CPU-/Speicherverfügbarkeit aus.
3. Sichere Kommunikation zwischen Mitwirkende und Aggregatoren durch die Add-on-Registrierung von OCM
Der Add-on-Collaborator für FL wird auf den verwalteten Clustern bereitgestellt und nutzt den Add-on-Registrierungsmechanismus von OCM, um eine geschützte, verschlüsselte Kommunikation mit dem Aggregator im Hub herzustellen. Bei der Registrierung erhält jedes Collaborator-Add-on automatisch Zertifikate vom OCM-Hub. Diese Zertifikate authentifizieren und verschlüsseln die während des FL ausgetauschten Modellaktualisierungen und ermöglichen so Vertraulichkeit, Integrität und Datenschutz in mehreren Clustern.
Bei diesem Prozess werden KI-Trainingsaufgaben effizient nur ausreichend ausgestatteten Clustern zugewiesen und eine integrierte Clientauswahl auf der Basis von Datenlokalität und Ressourcenkapazität ermöglicht.
Der Trainings-Lifecycle von FL: OCM-gesteuerte Planung
Zur Verwaltung des Trainings-Lifecycles von FL in mehreren Clustern wurde ein dedizierter Federated Learning Controller entwickelt. Der Controller verwendet CRDs, um die Workflows zu definieren, und unterstützt beliebte FL-Runtimes wie Flower und OpenFL. Zudem ist er erweiterbar.
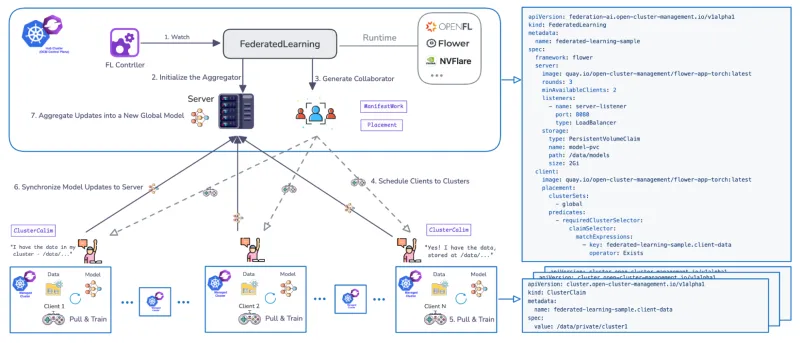

Der von OCM verwaltete Workflow durchläuft definierte Phasen:
Schritte | OCM/FL-Phase | Beschreibung |
0 | Prerequisite | Das Add-on für föderiertes Lernen ist installiert. Die FL-Anwendung ist als in Kubernetes bereitstellbarer Container verfügbar. |
1 | FederatedLearning CR | Auf dem Hub wird eine benutzerdefinierte Ressource erstellt, die das Framework (z. B. Flower), die Anzahl der Trainingsrunden (jeweils ein vollständiger Zyklus, in dem die Clients lokal trainieren und Aktualisierungen zur Aggregation zurückgeben), die erforderliche Anzahl verfügbarer Trainingsmitwirkender und die Modell-Storage-Konfiguration definiert (z. B. Angabe eines PersistentVolumeClaim-Pfads (PVC)). |
2, 3, 4 | Waiting & Scheduling | Der Ressourcenstatus lautet „Waiting“. Der Server (Aggregator) wird auf dem Hub initialisiert, und der OCM-Controller verwendet Placement, um Clients (Mitarbeitende) zu planen. |
5, 6 | Running | Der Status ändert sich in „Running“. Clients rufen das globale Modell ab, trainieren das Modell lokal mit privaten Daten und synchronisieren Modellaktualisierungen zurück mit dem Modellaggregator. Der Parameter der Trainingsrunden bestimmt, wie oft sich diese Phase wiederholt. |
7 | Completed | Der Status erreicht „Completed“. Die Validierung kann durch das Bereitstellen von Jupyter Notebooks durchgeführt werden, um die Performance des Modells anhand des gesamten aggregierten Datensatzes zu verifizieren (z. B. Bestätigung, dass es alle geänderten Ziffern des National Institute of Standards and Technology (MNIST) vorhersagt). |
Red Hat Advanced Cluster Management: Unternehmenskontrolle und operativer Mehrwert für FL-Umgebungen
Die von OCM bereitgestellten zentralen APIs und die Architektur bilden die Basis von Red Hat Advanced Cluster Management for Kubernetes. Red Hat Advanced Cluster Management bietet Lifecycle Management für eine homogene FL-Plattform (Red Hat OpenShift) in einer heterogenen Infrastruktur. Die Ausführung des FL-Controllers auf Red Hat Advanced Cluster Management bietet zusätzliche Vorteile, die über die Vorteile von OCM allein hinausgehen. Red Hat Advanced Cluster Management sorgt für zentralisierte Transparenz, richtliniengesteuerte Governance und Lifecycle Management in Multicluster-Umgebungen und verbessert die Verwaltbarkeit verteilter FL-Umgebungen.
1. Beobachtbarkeit
Red Hat Advanced Cluster Management bietet einen einheitlichen Überblick über verteilte FL-Workflows, sodass Operatoren den Trainingsfortschritt, den Clusterstatus und die clusterübergreifende Koordination über eine einzige, konsistente Oberfläche überwachen können.
2. Verbesserte Konnektivität und Sicherheit
Die CRD für FL unterstützt die geschützte Kommunikation zwischen dem Aggregator und den Clients über TLS-aktivierte Kanäle. Es bietet außerdem flexible Netzwerkoptionen über NodePort hinaus, einschließlich LoadBalancer, Route und anderen Ingress-Typen, und sorgt so für geschützte und anpassbare Konnektivität in heterogenen Umgebungen.
3. End-to-End-Integration von ML-Lifecycle mit Red Hat Advanced Cluster Management und Red Hat OpenShift AI
Durch den Einsatz von Red Hat Advanced Cluster Management mit OpenShift AI können Unternehmen einen vollständigen FI-Workflow erstellen – vom Modell-Prototyping und verteiltem Training bis hin zu Validierung und Produktionsbereitstellung – innerhalb einer einheitlichen Plattform.
Zusammenfassung
FL transformiert die KI, indem das Modelltraining direkt auf die Daten verlagert wird und so die Reibungspunkte zwischen Rechenumfang, Datenübertragung und strengen Datenschutzanforderungen effektiv beseitigt werden. Im Folgenden wird erläutert, wie Red Hat Advanced Cluster Management die Orchestrierung, den Schutz und die Beobachtbarkeit bietet, die für das Verwalten komplexer verteilter Kubernetes-Umgebungen erforderlich sind.
Kontaktieren Sie Red Hat, um herauszufinden, wie Sie Ihr Unternehmen mit föderiertem Lernen unterstützen können.
Ressource
Das adaptive Unternehmen: KI-Bereitschaft heißt Disruptionsbereitschaft
Über die Autoren

Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.
Ähnliche Einträge
KI im Jahr 2026: Zwischen Hype, Verantwortung und echter Wertschöpfung
AI insights with actionable automation accelerate the journey to autonomous networks
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen