Es sind mehr als 2 Jahre vergangen, seit wir über die Automatisierung von In-Place-Upgrades für Red Hat Enterprise Linux (RHEL) berichtet haben. In dieser Zeit haben Dutzende von Kunden Hunderttausende von Systemen mithilfe unseres präskriptiven, automatisierten Ansatzes aktualisiert, um RHEL Upgrades in großem Umfang durchzuführen. In diesem Artikel geben wir einen kurzen Überblick über die wichtigsten Funktionen, die die Einführung der Automatisierung von RHEL Upgrades beschleunigen. Wir sehen uns an, was gut funktioniert hat, aber auch Herausforderungen und Lektionen, die wir gelernt haben.
Die zentrale Erkenntnis: Schnell scheitern, iterieren und es erneut versuchen. Das Entscheidende dabei ist, dass der Upgrade-Prozess weniger beängstigend ist und eine schnelle Wiederherstellung des ursprünglichen Zustands ermöglicht, auch wenn mal nicht alles perfekt läuft.
Die Herausforderung
Viele unserer großen Kunden verfügen über umfangreiche RHEL-Umgebungen, die seit Beginn der Einführung von Linux in Unternehmen Anfang 2000 über Jahrzehnte hinweg gewachsen sind und sich weiterentwickelt haben. Unternehmen haben mit den besten Absichten versucht, das Deployment und die Verwaltung von Anwendungs-Workloads zu modernisieren, indem sie auf Virtualisierung und Containerisierung gesetzt haben. Einige verfügen jedoch nach wie vor über eine große Anzahl von RHEL-Hosts, die diesen Anschluss noch nicht geschafft haben. Diese Anwendungen werden auf individuell verwalteten Servern ausgeführt, die über Jahre hinweg sorgfältig gepflegt wurden, wobei manuelle Änderungen zu einer großen Ansammlung von nicht nachverfolgten Abweichungen führten.
Es ist die Schwierigkeit, Änderungen an diesen Anwendungsumgebungen vorzunehmen, die Unternehmen an älteren Versionen von RHEL festhalten lässt. Das Replatforming auf eine neue RHEL-Version ist für Infrastruktur- und Operations-Teams im Allgemeinen einfach, aber das erneute Bereitstellen von individuell verwalteten Anwendungen ist für Anwendungsteams eine mühsame Aufgabe. Sich aus all den technischen Altlasten herauszuarbeiten, um herauszufinden, wie man ihre Arbeitslasten sicher neu verteilen kann, erweist sich als sehr kostspielig und risikobehaftet. Deshalb sind schnelles Scheitern und Lernen ein so entscheidender Teil des Puzzles.
Fazit: Es gibt eine einfachere Möglichkeit, Umgebungen auf eine neue RHEL-Version zu verschieben, ohne die Anwendungen ändern zu müssen. Bei einer Implementierung in großem Umfang summieren sich die Kosteneinsparungen im gesamten Unternehmen schnell.
Die Lösung
Unser Ansatz zur Skalierung von RHEL Upgrades ist die Automatisierung mit Red Hat Ansible Automation Platform und Ansible Validated Content. Diese Automatisierungen können Upgrades von RHEL 6 auf 7 bis hin zum aktuellen RHEL 9 auf 10 und alles dazwischen durchführen. Wir haben sogar gesehen, wie Kunden Multi-Hop-Upgrades wie RHEL 7 zu RHEL 9 in einem einzigen Wartungsfenster automatisieren.
Die Lösung basiert auf 4 wesentlichen Features.
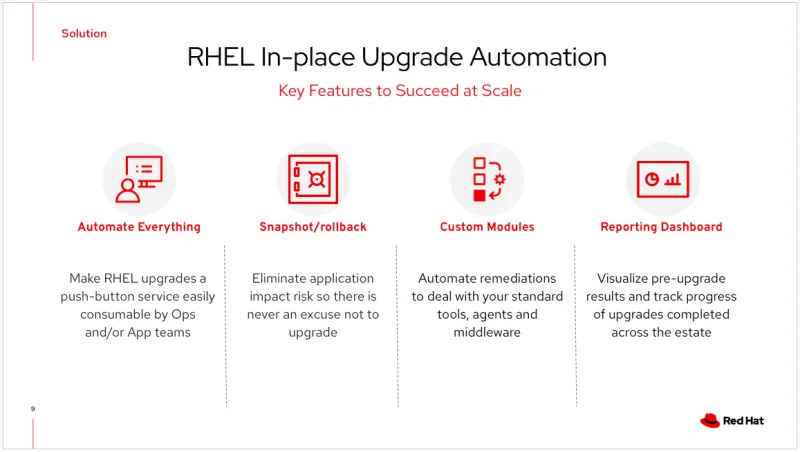
1. Alles automatisieren
Die End-to-End-Automatisierung für RHEL Upgrades macht den Prozess als benutzerfreundlichen Service auf Knopfdruck sowohl für Operations- als auch für Anwendungsteams verfügbar und wiederholbar.
2. Snapshot mit Rollback
Dies ist ein entscheidendes Merkmal dieses Ansatzes, da es das Risiko für Auswirkungen auf die Anwendung minimiert. Es gibt also keine Ausrede, kein Upgrade durchzuführen. Snapshots können je nach Umgebung mit LVM (Logical Volume Manager), VMware-Snapshots oder ReaR-Backups (Relax-and-Recover) automatisiert werden. Rollbacks ermöglichen es Ihnen, schnell zu scheitern und es erneut zu versuchen.
3. Benutzerdefinierte Module
Während das RHEL-Leapp-Framework das Betriebssystem selbst aktualisiert, erfordert die Entwicklung einer benutzerdefinierten Automatisierung, die Besonderheiten Ihrer Umgebung zu berücksichtigen, wie z. B. Standardtools und -Agenten von Drittanbietern.
4. Reporting-Dashboard (optional, aber sehr nützlich)
Das Reporting-Dashboard verfolgt die Upgrade-Ergebnisse im gesamten RHEL-Bestand. Es visualisiert die von Leapp generierten Pre-Upgrade-Berichte und erleichtert so die Analyse von Ergebnissen und aggregierte Metriken zum Volumen und Fortschritt der abgeschlossenen Upgrades.
Erkenntnisse aus der Automatisierung von einer Million RHEL-In-Place-Upgrades
Wenn wir bei der Unterstützung unserer Kunden bei der Implementierung dieses Ansatzes etwas gelernt haben, dann ist es, dass nichts auf Anhieb perfekt funktioniert. Es gibt keine Möglichkeit, die „Snowflake“-Konfigurationen, die Auswirkungen von Low-Level-Drittanbieterprodukten, die externen Umgebungsfaktoren usw. vorherzusehen. Wir haben festgestellt, dass es ratsam ist, direkt in die Upgrades einzusteigen und mit den niedrigeren Lab- und Entwicklungsumgebungen zu beginnen.
Wir nennen das den „Fail-Fast“-Ansatz, und er ist der Schlüssel zur schnellen Entwicklung einer Lösung, damit sie letztendlich alle spezifischen Variationen für Ihre Umgebung handhabt. Es handelt sich dabei um eine Methodik, die schnelles Lernen und schnelle Iterationen ermöglicht, indem Upgrades bewusst durchgeführt werden, in der Erwartung, dass etwas fehlschlägt. Dann beobachtet man diese Fehler, setzt schnell zurück und nutzt das Gelernte, um die Automatisierung ausfallsicher zu machen.
Aus folgenden Gründen ist der Fail-Fast-Ansatz für die Automatisierung von In-Place-Upgrades in RHEL entscheidend:
- Risikominderung und Vertrauensbildung
- Das entscheidende Element zur Risikominderung ist die Funktion zum Rollback von Snapshots. Dies mindert die Sorge, dass ein Upgrade für Anwendungsteams zu riskant ist. Falls etwas schiefgeht, lässt sich das System schnell in seinen vorherigen Zustand zurückversetzen, ohne dass es dabei zu einem längeren Ausfall kommt. Diese Funktion zur schnellen Wiederherstellung ermöglicht Anwendungsteams schnelle Upgrades und die Behebung eines wichtigen Problems im Zusammenhang mit Compliance- und gesetzlichen Anforderungen in Branchen wie dem Bankwesen.
- Bei einem bekannten Kunden testete ein Anwendungsteam, einen Host mehrmals zu aktualisieren und zurückzusetzen, um Vertrauen in den Snapshot-Prozess zu gewinnen. Sie haben sogar absichtlich Dinge kaputt gemacht, bevor sie ein Rollback durchgeführt haben, nur um das Ganze zu beweisen.
- Ein großer Bankkunde sah einen „Hiccup“ während seines ersten Bare Metal-Upgrades ebenfalls als Erfolg an, da das Rollback funktionierte und die Fail-Fast-Methodik validierte.
- Ein anderer Kunde mit einem kleineren Bestand hat innerhalb von nur zwei Wochen erfolgreich alle 60 seiner RHEL-Hosts aktualisiert – nach dem Motto „schnell handeln, Fehler in Kauf nehmen“ und dabei auf Automatisierung und Rollback setzen.
- Beschleunigte Entwicklung und optimierte Automatisierung
- Fail-Fast beschleunigt die Entwicklung von benutzerdefinierter Automatisierung, da Teams schnelle Iterationen durchführen können. Anstatt zu versuchen, mögliche Probleme vorherzusehen, ermutigt der Ansatz dazu, das Upgrade durchzuführen, mögliche Fehler zu beobachten, ein Rollback durchzuführen, einen Fix zu automatisieren und anschließend den Vorgang zu wiederholen.
- Dies hilft, Lösungen für komplexe benutzerdefinierte Anforderungen zu identifizieren und zu optimieren, z. B. den Umgang mit Tools, Agents und Middleware von Drittanbietern, die möglicherweise nicht mit der neuen RHEL-Version kompatibel sind. Ein anderer Bankkunde nutzte dies beispielsweise, um Drittanbieterpakete zu identifizieren, die durch Upgrades entfernt wurden, und deren Neuinstallation zu automatisieren.
- Dieser Ansatz ermöglicht es, „Echtexemplare“ – also unerwartete Abweichungen und Variationen in einer Umgebung – zu entdecken und anschließend die Automatisierung entsprechend zu verfeinern.
- Organisatorische Hindernisse überwinden
- Versagen kann ein Stigma mit sich bringen, das zu übermäßig risikoscheuem Verhalten führt. Der Fail-Fast-Ansatz, der durch eine robuste Rollback-Funktion unterstützt wird, hilft, dies zu überwinden, indem er zeigt, dass Fehler nicht nur schnell und sicher behoben werden können, sondern auch einen schnellen Lernansatz ermöglichen.
- Wenn Red Hat bei skeptischen zentralen IT- oder Operations-Teams auf Zögern stößt, hilft es, den Fail-Fast-Ansatz und seine Vorteile für Anwendungsteams zu betonen. Es zeigt, wie die Lösung sie unterstützt, ohne ein kostspieliges Replatforming zu erzwingen.
- Skalieren
- Durch das schnelle Identifizieren und Beheben von Problemen durch iterative Tests können Unternehmen ihre Upgrade-Geschwindigkeit erhöhen. Ein Kunde mit einem RHEL-Bestand von mehr als 100.000 Instanzen konnte beispielsweise mithilfe von Self Service-Automatisierung, die schnelle Iteration und Rollback ermöglicht, weltweit 8.000 Upgrades pro Monat erreichen.
- Die Möglichkeit, die Automatisierung in niedrigeren Umgebungen (Lab und Entwicklung) zu testen und zu optimieren, bevor sie in die Produktion übergeht, ist eine Best Practice, um Ausfälle zu vermeiden und ein hohes Volumen an Upgrades zu erreichen.
Die zentralen Komponenten zur Unterstützung von Fail-Fast im Detail:
- Automatisierte Snapshot- und Rollback-Funktionen: Das ist die Grundlage des Fail-Fast-Ansatzes. Zu den Optionen gehören LVM-Snapshots oder VMware-Snapshots. ReaR-Backups können auch für einen doppelt abgesicherten Ansatz verwendet werden, falls ein Snapshot-Rollback nicht funktioniert.
- Benutzerdefinierte Module und Automatisierung: Die offiziellen Leapp-System-Upgrade-Repositories und ihre Akteure übernehmen das Upgrade des Betriebssystems. Die Verwaltung von Drittanbietertools, Agents und Middleware, die für die Umgebung eines Kunden spezifisch sind, erfordert jedoch benutzerdefinierte Ansible-Aufgaben oder zusätzliche benutzerdefinierte Leapp-Akteure. Man verfeinert diese benutzerdefinierten Automatisierungen durch Fail-Fast-Iterationen.
- Reporting-Dashboards: Tools wie Elastic oder Splunk können die Ergebnisse vor dem Upgrade visualisieren und den Fortschritt von Upgrades verfolgen. So können Teams häufige Probleme identifizieren und ihre Automatisierung optimieren.
Mehr über RHEL Upgrades erfahren
Mit einem Fail-Fast-Ansatz verwandelt man die scheinbar herausfordernde Aufgabe umfangreicher RHEL Upgrades in einen iterativen Prozess, der Lernen und Sicherheit priorisiert, was letztlich eine erhebliche Geschwindigkeit ermöglicht und die Compliance schnell verbessert.
- So automatisieren Sie Upgrades vor dem Ende des Wartungssupports von RHEL 7
- End of Maintenance für Red Hat Enterprise Linux 7 nähert sich
- infra.leapp Git repo: Eine Sammlung von Ansible Roles zur Automatisierung von In-Place-Upgrades für RHEL, unterstützt von einer erfolgreichen Upstream Community. Diese Rollen bieten standardisierte Methoden für die Verwendung des Leapp-Frameworks zur Durchführung der Analyse vor dem Upgrade und des RHEL Upgrades selbst. Wenn Sie bereit sind, eigene benutzerdefinierte Playbooks zur Ausführung von Upgrades für Ihr Unternehmen zu entwickeln, sollten Sie die Rollen aus dieser Ansible Collection verwenden, um Ihre Arbeit zu erleichtern.
- infra.lvm_snapshots Ansible Collection: Ein wichtiger Baustein für die Automatisierung von In-Place-Upgrades in RHEL, der die Rollen speziell für die LVM-Snapshot-Verwaltung bereitstellt. Diese Sammlung bietet wichtige Funktionen wie snapshot_create zum Erstellen von definierten Gruppen von LVM-Snapshot-Volumes, snapshot_remove zum Löschen und snapshot_revert, um ein System sofort in einen zuvor erfassten Zustand zurückzusetzen. Es enthält auch Rollen wie shrink_lv zum sicheren Verkleinern logischer Volumes, um Speicherplatz für Snapshots freizugeben, und bigboot zum Vergrößern der Boot-Partition.
- ripu-splunk repo: Bietet eine Referenzimplementierung für Reporting-Dashboards, die die Automatisierungslösungen für RHEL Upgrades verbessern sollen. Diese Open Source Collection bietet Beispiele, die in Splunk Dashboard Studio importiert werden können, darunter eine Zusammenfassung vor dem Upgrade, einen detaillierten Bericht vor dem Upgrade und einen Zeitplan für den Upgrade-Fortschritt.
Wir helfen Ihnen gerne
Während sich automatisierte Upgrades in den letzten Jahren weiterentwickelt haben, sind Red Hat Consulting Services maßgeblich daran beteiligt gewesen, viele Kunden beim Rollout der Lösung zu unterstützen. Wenn Sie der Gedanke an ein Upgrade einer großen Umgebung überfordert oder Sie unsicher sind, wo Sie anfangen sollen, können Ihnen die Red Hat Consulting Services mit ihrem Fachwissen und ihrer Beratung dabei helfen, dieses Ziel zu erreichen, und Ihnen dabei möglicherweise Zeit und Geld sparen.
Produkttest
Red Hat Ansible Automation Platform | Testversion
Über die Autoren

Bob is an industry veteran with a lifetime of experience in IT dating back to the 1980s. Before coming to Red Hat in 2022, he held software consulting roles at DEC/HP and later moved to the banking industry as a pioneer leading Wall Street's early adoption of Linux. Today as a member of Red Hat's Customer-led Open Innovation team, he is committed to growing the community that's developing automation to make RHEL in-place upgrades successful at enterprise scale.

Bob Handlin has helped build and promote products in various parts of the tech industry for more than 20 years. He currently focuses on RHEL migrations and upgrades, but also assists with storage technologies and live patching.
Ähnliche Einträge
AI insights with actionable automation accelerate the journey to autonomous networks
IT automation with agentic AI: Introducing the MCP server for Red Hat Ansible Automation Platform
Technically Speaking | Taming AI agents with observability
Get into GitOps | Technically Speaking
Nach Thema durchsuchen

Automatisierung
Das Neueste zum Thema IT-Automatisierung für Technologien, Teams und Umgebungen

Künstliche Intelligenz
Erfahren Sie das Neueste von den Plattformen, die es Kunden ermöglichen, KI-Workloads beliebig auszuführen

Open Hybrid Cloud
Erfahren Sie, wie wir eine flexiblere Zukunft mit Hybrid Clouds schaffen.

Sicherheit
Erfahren Sie, wie wir Risiken in verschiedenen Umgebungen und Technologien reduzieren

Edge Computing
Erfahren Sie das Neueste von den Plattformen, die die Operations am Edge vereinfachen

Infrastruktur
Erfahren Sie das Neueste von der weltweit führenden Linux-Plattform für Unternehmen

Anwendungen
Entdecken Sie unsere Lösungen für komplexe Herausforderungen bei Anwendungen
Virtualisierung
Erfahren Sie das Neueste über die Virtualisierung von Workloads in Cloud- oder On-Premise-Umgebungen