La era moderna del entrenamiento de la inteligencia artificial, en especial para los modelos de gran tamaño, enfrenta exigencias simultáneas de escalabilidad informática y privacidad estricta de los datos. El machine learning (ML) tradicional requiere la centralización de los datos de entrenamiento, lo que genera obstáculos y esfuerzos importantes en relación con la privacidad y la seguridad de los datos, y la eficiencia o el volumen de los datos.
Este desafío se agrava en las infraestructuras globales heterogéneas de los entornos multicloud, de nube híbrida y edge, por lo que las empresas deben entrenar los modelos con los conjuntos de datos distribuidos actuales y, al mismo tiempo, proteger la privacidad de los datos.
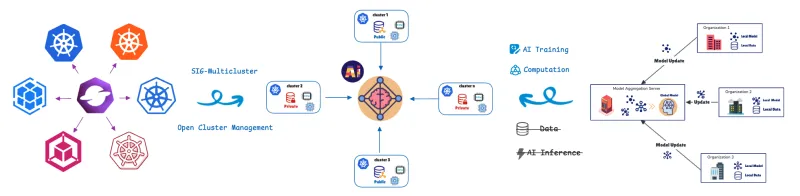
El aprendizaje federado (FL) aborda este desafío trasladando el entrenamiento del modelo a los datos. Los clústeres o los dispositivos remotos (colaboradores o clientes) entrenan los modelos de forma local con sus datos privados y solo comparten las actualizaciones de los modelos (no los datos sin procesar) con un servidor central (agregador). Esto ayuda a proteger la privacidad de los datos de manera integral. Este enfoque es fundamental para los casos en los que la privacidad o la carga de datos son importantes, como en el sector de la salud, el comercio minorista, la automatización industrial y los vehículos definidos por software (SDV) con sistemas avanzados de asistencia al conductor (ADAS) y funciones de conducción autónoma (AD), como la advertencia de salida de carril, el control de crucero adaptativo y la supervisión de la fatiga del conductor.
Para gestionar y organizar estas unidades informáticas distribuidas, utilizamos la definición de recursos personalizados (CRD) de aprendizaje federado de Open Cluster Management (OCM).
OCM: la base para las operaciones distribuidas
OCM es una plataforma de organización de multiclústeres de Kubernetes y un proyecto open source CNCF Sandbox project.
OCM emplea una arquitectura de tipo hub-spoke y utiliza un modelo basado en pull.
- Clúster hub: actúa como el plano de control central (plano de control de OCM) responsable de la organización.
- Clústeres gestionados (spoke): son clústeres remotos en los que se implementan las cargas de trabajo.
Los clústeres gestionados extraen su estado deseado y envían el estado de vuelta al hub. OCM proporciona API como ManifestWork y Placement para programar las cargas de trabajo. A continuación, veremos más detalles sobre la API de aprendizaje federado.
Ahora veremos por qué y cómo el diseño de gestión de clústeres distribuidos de OCM se alinea estrechamente con los requisitos de implementación y gestión de los colaboradores de FL.
Integración nativa: OCM como orquestador de FL
1. Adaptación de la arquitectura
La combinación de OCM y FL es eficaz debido a su congruencia estructural fundamental. OCM admite de forma nativa FL porque ambos sistemas comparten un diseño base idéntico: la arquitectura hub-spoke y un protocolo basado en pull.
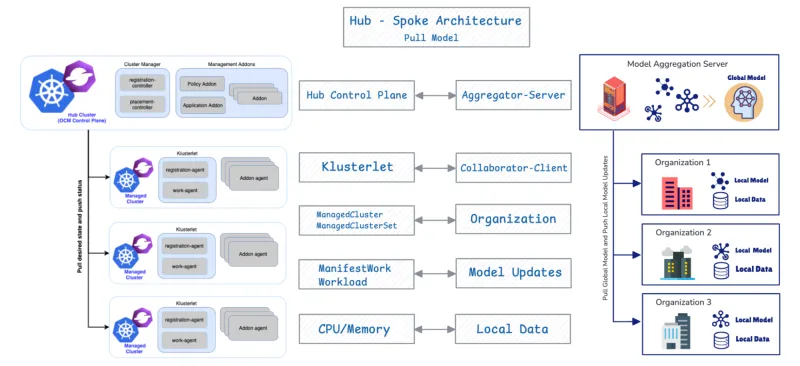
Componente de OCM | Componente de FL | Función |
Plano de control del hub de OCM | Agregador/Servidor | Orquesta el estado y agrega las actualizaciones del modelo. |
Clúster gestionado | Colaborador/Cliente | Extrae el estado deseado o el modelo global, entrena localmente y envía las actualizaciones. |
2. Ubicación flexible para la selección de clientes multiactor
La principal ventaja operativa de OCM es su capacidad para automatizar la selección de clientes en configuraciones de FL aprovechando sus funciones flexibles de programación entre clústeres. Esta función utiliza la API Placement de OCM para implementar políticas sofisticadas que cumplen varios criterios, lo cual brinda eficiencia y cumplimiento de la privacidad al mismo tiempo.
La API Placement permite la selección integrada de clientes en función de los siguientes factores:
- Ubicación de los datos (criterio de privacidad): las cargas de trabajo de FL se programan solo en los clústeres gestionados que afirman tener los datos privados necesarios.
- Optimización de recursos (criterio de eficiencia): la estrategia de programación de OCM ofrece políticas flexibles que permiten la evaluación combinada de varios factores. Selecciona los clústeres no solo en función de la presencia de datos, sino también de los atributos anunciados, como la disponibilidad de CPU o memoria.
3. Comunicación segura entre colaborador y agregador mediante el registro de complementos de OCM
El add-on FL Collaborator se implementa en los clústeres gestionados y aprovecha el mecanismo de registro de complementos de OCM para establecer una comunicación cifrada y protegida con el agregador en el hub. Tras el registro, cada add-on de colaborador obtiene automáticamente los certificados del hub de OCM. Estos certificados autentican y cifran todas las actualizaciones de los modelos que se intercambian durante FL, lo que garantiza la confidencialidad, la integridad y la privacidad en varios clústeres.
Este proceso asigna de manera eficiente las tareas de entrenamiento de la inteligencia artificial solo a los clústeres con los recursos adecuados, lo que proporciona una selección de clientes integrada basada tanto en la ubicación de los datos como en la capacidad de los recursos.
El ciclo de vida del entrenamiento de FL: programación basada en OCM
Se desarrolló un controlador de Federated Learning exclusivo para gestionar el ciclo de vida del entrenamiento de FL en varios clústeres. El controlador utiliza las CRD para definir los flujos de trabajo, admite los tiempos de ejecución conocidos de FL, como Flower y OpenFL, y es extensible.
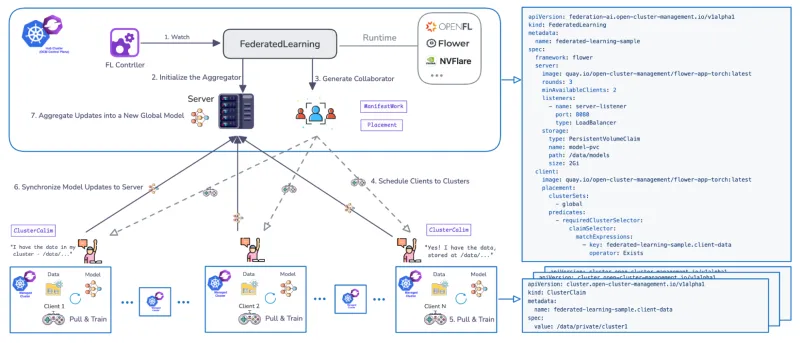

El flujo de trabajo gestionado por OCM avanza a través de etapas definidas:
Pasos | Fase de OCM/FL | Descripción |
0 | Requisito previo | El complemento de aprendizaje federado está instalado. La aplicación de FL está disponible como un contenedor que se puede implementar en Kubernetes. |
1 | FederatedLearning CR | Se crea un recurso personalizado en el hub que define el marco (por ejemplo, flower), el número de rondas de entrenamiento (cada ronda es un ciclo completo en el que los clientes se entrenan localmente y devuelven las actualizaciones para su agregación), el número necesario de colaboradores de entrenamiento disponibles y la configuración de almacenamiento del modelo (por ejemplo, especificando una ruta de PersistentVolumeClaim [PVC]). |
2, 3, 4 | Espera y programación | El estado del recurso es “Waiting”. El servidor (agregador) se inicializa en el hub, y el controlador de OCM utiliza Placement para programar los clientes (colaboradores). |
5, 6 | En ejecución | El estado cambia a “Running”. Los clientes extraen el modelo global, entrenan el modelo localmente con datos privados y sincronizan las actualizaciones del modelo de vuelta al agregador de modelos. El parámetro de rondas de entrenamiento determina la frecuencia con la que se repite esta fase. |
7 | Completada | El estado es “Completed”. La validación se puede llevar a cabo mediante la implementación de Jupyter Notebooks para verificar el rendimiento del modelo con todo el conjunto de datos agregados (por ejemplo, confirmando que predice todos los dígitos del Instituto Nacional Modificado de Estándares y Tecnología [MNIST]). |
Red Hat Advanced Cluster Management: control empresarial y valor operativo para entornos de FL
La arquitectura y las API principales que proporciona OCM sirven como base de Red Hat Advanced Cluster Management for Kubernetes. Red Hat Advanced Cluster Management permite gestionar el ciclo de vida de una plataforma de FL homogénea (Red Hat OpenShift) en un entorno de infraestructura heterogéneo. La ejecución del controlador de FL en Red Hat Advanced Cluster Management ofrece beneficios adicionales a los que ofrece OCM por sí solo. Red Hat Advanced Cluster Management ofrece visibilidad centralizada, gobernanza basada en políticas y gestión del ciclo de vida en entornos multiclúster, lo que mejora considerablemente la capacidad de gestión de los entornos distribuidos y de FL.
1. Observabilidad
Red Hat Advanced Cluster Management ofrece observabilidad unificada en los flujos de trabajo de FL distribuidos, lo que permite a los operadores supervisar el progreso del entrenamiento, el estado del clúster y la coordinación entre clústeres desde una interfaz única y coherente.
2. Conectividad y seguridad mejoradas
La CRD de FL admite la comunicación protegida entre el agregador y los clientes a través de canales habilitados para TLS. También ofrece opciones de red flexibles más allá de NodePort, incluidas LoadBalancer, Route y otros tipos de entrada, lo que proporciona una conectividad protegida y adaptable en entornos heterogéneos.
3. Integración integral del ciclo de vida de ML con Red Hat Advanced Cluster Management y Red Hat OpenShift AI
Al aprovechar Red Hat Advanced Cluster Management con OpenShift AI, las empresas pueden diseñar un flujo de trabajo de FL completo, desde la creación de prototipos de modelos y el entrenamiento distribuido hasta la validación y la implementación en producción, dentro de una plataforma unificada.
Conclusión
FL está transformando la inteligencia artificial al trasladar el entrenamiento de modelos directamente a los datos, lo que resuelve de manera efectiva la fricción entre la escala computacional, la transferencia de datos y los estrictos requisitos de privacidad. Aquí destacamos cómo Red Hat Advanced Cluster Management proporciona la orquestación, la protección y la observabilidad necesarias para gestionar entornos complejos de Kubernetes distribuidos.
Ponte en contacto con Red Hat hoy mismo para explorar cómo puedes impulsar tu empresa con el aprendizaje federado.
Recurso
La empresa adaptable: Motivos por los que la preparación para la inteligencia artificial implica prepararse para los cambios drásticos
Sobre los autores

Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.
Más como éste
AI insights with actionable automation accelerate the journey to autonomous networks
Fast and simple AI deployment on Intel Xeon with Red Hat OpenShift
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Navegar por canal

Automatización
Las últimas novedades en la automatización de la TI para los equipos, la tecnología y los entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones
Virtualización
El futuro de la virtualización empresarial para tus cargas de trabajo locales o en la nube