L'era moderna dell'addestramento dell'IA, in particolare per i modelli di grandi dimensioni, si trova ad affrontare contemporaneamente richieste di scalabilità computazionale e di conformità ai rigidi requisiti sulla privacy dei dati. Il machine learning (ML) tradizionale richiede la centralizzazione dei dati di addestramento, creando notevoli ostacoli e lavoro intorno alla privacy, alla sicurezza, all'efficienza e al volume dei dati.
Questa sfida aumenta in un'infrastruttura globale eterogenea in presenza di ambienti multicloud, hybrid cloud ed edge computing. Per questo motivo, le organizzazioni devono addestrare i modelli utilizzando i set di dati distribuiti esistenti e proteggere la privacy dei dati.
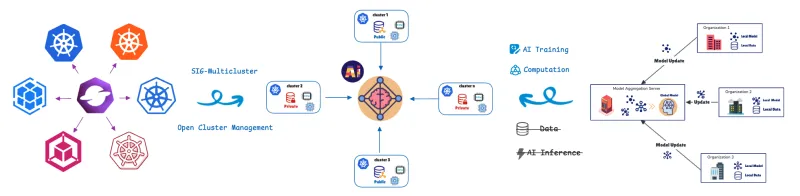
Il federated learning (FL) affronta questa sfida spostando l'addestramento del modello sui dati. I cluster o i dispositivi remoti (collaboratori/client) addestrano i modelli localmente utilizzando i loro dati privati e condividono solo gli aggiornamenti dei modelli (non i dati non elaborati) con un server centrale (aggregatore). Questo aiuta a proteggere la privacy dei dati in modo completo. Questo approccio è fondamentale per gli scenari sensibili alla privacy o con carichi di dati elevati, che si riscontrano nei settori sanitario, della vendita al dettaglio, dell'automazione industriale e dei veicoli software-defined (SDV) con sistemi avanzati di assistenza alla guida (ADAS) e funzionalità di guida autonoma (AD), come l'avviso di deviazione dalla corsia, il cruise control adattivo e il monitoraggio dell'affaticamento del conducente.
Per gestire e orchestrare queste unità di calcolo distribuite, utilizziamo la definizione di risorse personalizzate (CRD) di federated learning di Open Cluster Management (OCM).
OCM: una base per operazioni distribuite
OCM è una piattaforma di orchestrazione multicluster Kubernetes e un progetto open source CNCF Sandbox.
OCM adotta un'architettura hub-spoke e utilizza un modello pull-based.
- Cluster hub: funge da piano di controllo centrale (OCM Control Plane) responsabile dell'orchestrazione.
- Cluster gestiti (spoke): sono cluster remoti in cui vengono distribuiti i carichi di lavoro.
I cluster gestiti eseguono il pull del loro stato desiderato e segnalano il loro stato all'hub. OCM fornisce API come ManifestWork e Placement per pianificare i carichi di lavoro. Forniremo maggiori dettagli sulle API di federated learning più avanti.
Ora analizzeremo il motivo e le modalità per cui la progettazione della gestione dei cluster distribuiti di OCM si allinea strettamente ai requisiti di distribuzione e gestione dei contributori FL.
Integrazione nativa: OCM come orchestrator FL
1. Allineamento architetturale
La combinazione di OCM e FL è efficace grazie alla loro fondamentale congruenza strutturale. OCM supporta FL in modo nativo, poiché entrambi i sistemi condividono una progettazione di base identica: l'architettura hub-spoke e un protocollo pull-based.
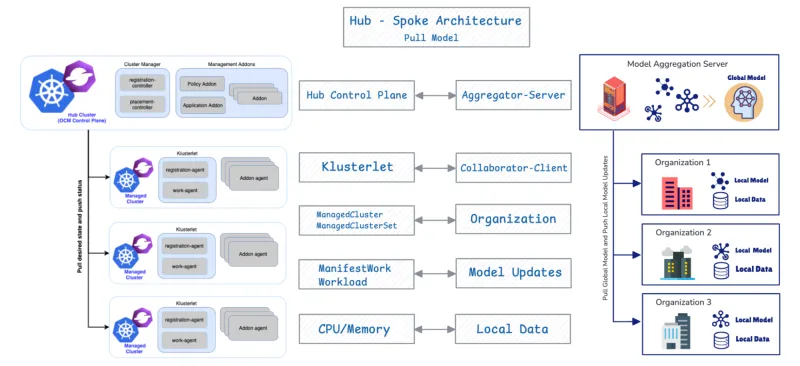
Componente OCM | Componente FL | Funzione |
Piano di controllo dell'hub OCM | Aggregatore/server | Orchestra lo stato e aggrega gli aggiornamenti dei modelli. |
Cluster gestito | Collaboratore/client | Esegue il pull dello stato/modello globale desiderato, addestra in locale e invia gli aggiornamenti. |
2. Posizionamento flessibile per la selezione di client multiactor
Il vantaggio operativo principale di OCM è la sua capacità di automatizzare la selezione dei client nelle configurazioni FL sfruttando le sue funzionalità flessibili di pianificazione cross-cluster. Questa funzionalità utilizza l'API Placement di OCM per implementare policy sofisticate e multicriterio, garantendo al contempo efficienza e conformità alla privacy.
L'API Placement consente la selezione integrata dei client in base ai seguenti fattori:
- Località dei dati (criterio di privacy): i carichi di lavoro FL vengono pianificati solo nei cluster gestiti che dichiarano di possedere i dati privati necessari.
- Ottimizzazione delle risorse (criterio di efficienza): la strategia di pianificazione di OCM offre policy flessibili che consentono la valutazione combinata di diversi fattori. Seleziona i cluster non solo in base alla presenza dei dati, ma anche in base ad attributi dichiarati, come la disponibilità di CPU/memoria.
3. Comunicazione sicura tra collaboratore e aggregatore tramite la registrazione dell'add-on OCM
L'add-on FL del collaboratore viene distribuito sui cluster gestiti e sfrutta il meccanismo di registrazione degli add-on di OCM per stabilire una comunicazione protetta e crittografata con l'aggregatore sull'hub. Al momento della registrazione, ogni add-on del collaboratore ottiene automaticamente i certificati dall'hub OCM. Questi certificati autenticano e crittografano tutti gli aggiornamenti dei modelli scambiati durante FL, garantendo riservatezza, integrità e privacy tra più cluster.
Questo processo assegna in modo efficiente le attività di addestramento dell'IA solo ai cluster con risorse adeguate, fornendo una selezione integrata dei client in base sia alla località dei dati che alla capacità delle risorse.
Il ciclo di vita dell'addestramento FL: pianificazione basata su OCM
È stato sviluppato un Federated Learning Controller dedicato per gestire il ciclo di vita dell'addestramento di FL su più cluster. Il controller utilizza i CRD per definire i workflow e supporta i runtime FL più comuni, come Flower e OpenFL, ed è estensibile.
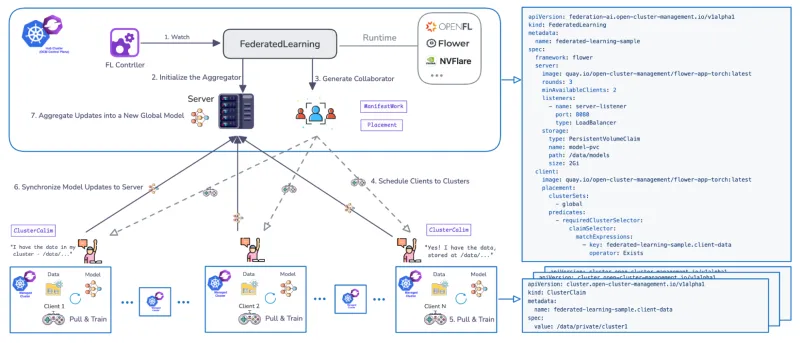

Il workflow gestito da OCM si sviluppa attraverso fasi definite:
Step | Fase OCM/FL | Descrizione |
0 | Prerequisito | L'add-on di federated learning è installato. L'applicazione FL è disponibile come container distribuibile di Kubernetes. |
1 | FederatedLearning CR | Una risorsa personalizzata viene creata sull'hub, definendo il framework (ad esempio, flower), il numero di round di addestramento (ogni round è un ciclo completo in cui i client si addestrano localmente e restituiscono gli aggiornamenti per l'aggregazione), il numero richiesto di contributori di addestramento disponibili e la configurazione dell'archiviazione del modello (ad esempio, specificando un percorso PersistentVolumeClaim, o PVC). |
2, 3, 4 | Attesa e pianificazione | Lo stato della risorsa è "In attesa". Il server (aggregatore) viene inizializzato sull'hub e il controller OCM utilizza Placement per pianificare i client (collaboratori). |
5, 6 | In esecuzione | Lo stato cambia in "In esecuzione". I client eseguono il pull del modello globale, addestrano il modello localmente sui dati privati e sincronizzano gli aggiornamenti del modello con l'aggregatore del modello. Il parametro dei round di addestramento determina la frequenza con cui questa fase si ripete. |
7 | Completato | Lo stato ora è "Completato". La convalida può essere eseguita distribuendo Jupyter Notebook per verificare le prestazioni del modello rispetto all'intero set di dati aggregati (ad esempio, confermando che prevede tutte le cifre del Modified National Institute of Standards and Technology, MNIST). |
Red Hat Advanced Cluster Management: controllo di livello enterprise e valore operativo per gli ambienti FL
Le API principali e l'architettura fornite da OCM fungono da base per Red Hat Advanced Cluster Management for Kubernetes. Red Hat Advanced Cluster Management offre la gestione del ciclo di vita per una piattaforma FL omogenea (Red Hat OpenShift) in un footprint infrastrutturale eterogeneo. L'esecuzione del controller FL su Red Hat Advanced Cluster Management offre ulteriori vantaggi rispetto a quelli offerti dal solo OCM. Red Hat Advanced Cluster Management offre visibilità centralizzata, governance basata su policy e gestione del ciclo di vita in ambienti multicluster, migliorando significativamente la gestibilità degli ambienti distribuiti e FL.
1. Osservabilità
Red Hat Advanced Cluster Management offre un'osservabilità unificata tra i workflow FL distribuiti, consentendo agli operatori di monitorare l'avanzamento dell'addestramento, lo stato del cluster e il coordinamento tra cluster da un'unica interfaccia coerente.
2. Connettività e sicurezza avanzate
Il CRD FL supporta la comunicazione protetta tra l'aggregatore e i client tramite canali abilitati TLS. Offre inoltre opzioni di rete flessibili oltre a NodePort, tra cui LoadBalancer, Route e altri tipi di ingressi, fornendo una connettività protetta e adattabile in ambienti eterogenei.
3. Integrazione del ciclo di vita ML end-to-end con Red Hat Advanced Cluster Management e Red Hat OpenShift AI
Sfruttando Red Hat Advanced Cluster Management con OpenShift AI, le aziende possono creare un workflow FL completo, dalla prototipazione del modello e l'addestramento distribuito, alla convalida e al deployment in produzione, all'interno di una piattaforma unificata.
Conclusioni
FL sta trasformando l'IA spostando l'addestramento del modello direttamente sui dati, risolvendo efficacemente l'attrito tra scalabilità computazionale, trasferimento dei dati e rigidi requisiti di privacy. In questa sezione abbiamo evidenziato come Red Hat Advanced Cluster Management fornisca l'orchestrazione, la protezione e l'osservabilità necessarie per gestire ambienti Kubernetes distribuiti complessi.
Contatta Red Hat oggi stesso per scoprire come potenziare la tua organizzazione con il federated learning.
Risorsa
L'adattabilità enterprise: predisporsi all'IA per essere pronti a un'innovazione radicale
Sugli autori

Andreas Spanner leads Red Hat’s Cloud Strategy & Digital Transformation efforts across Australia and New Zealand. Spanner has worked on a wide range of initiatives across different industries in Europe, North America and APAC including full-scale ERP migrations, HR, finance and accounting, manufacturing, supply chain logistics transformations and scalable core banking strategies to support regional business growth strategies. He has an engineering degree from the University of Ravensburg, Germany.

Meng Yan is a Senior Software Engineer at Red Hat, specializing in event-driven architectures for multi-cluster management at scale. His research interests focus on agentic AI systems and intelligent automation for software engineering, as well as AI/ML applications in distributed environments such as federated learning and multi-cluster inference.
Altri risultati simili a questo
AI insights with actionable automation accelerate the journey to autonomous networks
Fast and simple AI deployment on Intel Xeon with Red Hat OpenShift
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud