InstructLab è un progetto promosso dalla community e progettato per semplificare il processo di creazione e miglioramento dei modelli linguistici di grandi dimensioni (LLM) tramite la generazione di dati sintetici. Questa iniziativa prova a superare diverse sfide che gli sviluppatori devono affrontare, come le difficoltà incontrate nel contribuire agli LLM, la proliferazione dei modelli fork e la mancanza di una governance diretta della community. Supportato da Red Hat e IBM Research, InstructLab sfrutta nuovi metodi di ottimizzazione dell'allineamento basati su dati sintetici per migliorare le prestazioni e l'accessibilità dei modelli. In questo articolo illustreremo il problema attuale e le sfide tecniche che si incontrano durante il fine tuning dei modelli e l'approccio adottato da InstructLab per risolvere questi problemi.
Gli ostacoli: dati di bassa qualità e uso inefficiente delle risorse di elaborazione
Con l'intensificarsi della concorrenza nel settore degli LLM, l'approccio standard sembra essere quello di creare modelli sempre più grandi addestrati a partire da grandi quantità di informazioni provenienti dalla rete Internet pubblica. Tuttavia, gran parte delle risorse online include informazioni ridondanti o dati che non sono in linguaggio naturale, e che pertanto non contribuiscono alle funzionalità principali del modello.
Ad esempio, l'80% dei token utilizzati per addestrare l'LLM GPT-3, la base su cui vengono create le versioni successive, proviene da Common Crawl, che comprende un'enorme serie di pagine web. È noto che questo insieme di dati contiene un mix di testi di alta qualità e bassa qualità, script e altri dati non in linguaggio naturale. Si stima che una parte significativa dei dati possa essere costituita da contenuti non utili o di bassa qualità. (Analisi Common Crawl)
Il risultato di questa vasta rete di dati non selezionati è un uso inefficiente delle risorse di elaborazione. La conseguenza è un incremento dei costi di addestramento che ricade anche sugli utenti, oltre alla maggiore difficoltà nell'implementazione dei modelli negli ambienti locali.
Abbiamo riscontrato un numero crescente di modelli con meno parametri, in cui la qualità e la pertinenza dei dati sono più importanti della semplice quantità. I modelli con una selezione dei dati più precisa e accurata sono in grado di offrire prestazioni migliori, richiedono meno risorse di elaborazione e forniscono risultati di qualità superiore.
La soluzione di InstructLab: perfezionare la generazione di dati sintetici
La particolarità di InstructLab è la capacità di generare grandi quantità di dati per l'addestramento, partendo da un piccolo set di dati seed. Utilizza la metodologia Large-scale Alignment for chatBots (LAB), che migliora gli LLM riducendo al minimo i dati generati dall'uomo e il sovraccarico di elaborazione. In questo modo i singoli utenti possono contribuire in modo intuitivo con i dati pertinenti. Questi ultimi vengono poi migliorati con la generazione di dati sintetici, supportata da un modello dedicato.
Caratteristiche principali dell'approccio di InstructLab:
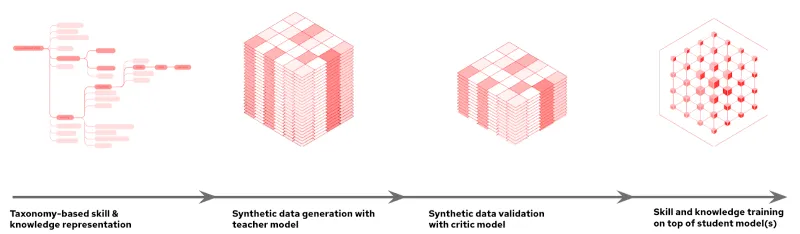
Selezione dei dati basata sulla tassonomia
Il percorso inizia con la creazione di una tassonomia, una struttura gerarchica che organizza diverse competenze e aree di conoscenza. Questa tassonomia consente di selezionare gli esempi generati dall'uomo, che fungono da base per la generazione dei dati sintetici. Questi dati sono organizzati in una struttura che semplifica l'esplorazione delle conoscenze del modello e l'individuazione delle lacune da colmare, riducendo al tempo stesso le informazioni ridondanti. Allo stesso tempo, consente di adattare un modello a uno scenario di utilizzo o a esigenze specifiche, utilizzando solo file YAML facili da formattare in coppie domanda-risposta.
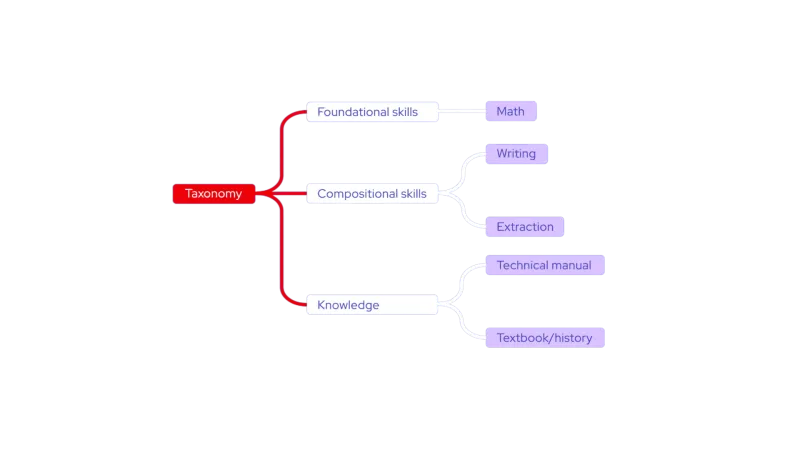
Il processo di generazione di dati sintetici
A partire dai dati iniziali di base, InstructLab sfrutta un modello "insegnante" per generare nuovi esempi durante il processo di generazione dei dati. È importante notare che questo processo non utilizza le conoscenze archiviate dal modello "insegnante", ma utilizza particolari prompt che ampliano notevolmente l'insieme di dati e, al contempo, garantisce che i nuovi esempi mantengano la struttura e l'intento dei dati originali non sintetici. La metodologia LAB sfrutta due specifici generatori di dati sintetici:
- Skills Synthetic Data Generator (Skills-SDG): utilizza modelli di prompt per la generazione di istruzioni e risposte e la valutazione generale e delle coppie finali.
- Knowledge-SDG: genera dati istruttivi per domini non coperti dal modello "insegnante", utilizzando fonti di conoscenza esterne come base per i dati generati.
Fortunatamente, questo riduce significativamente la necessità di grandi quantità di dati annotati manualmente. L'utilizzo di esempi piccoli, univoci e generati dall'uomo come riferimento consente di selezionare centinaia, migliaia o milioni di coppie di domande e risposte per influenzare i pesi e i pregiudizi del modello.
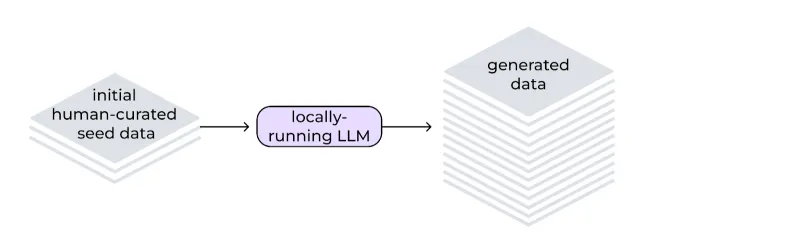
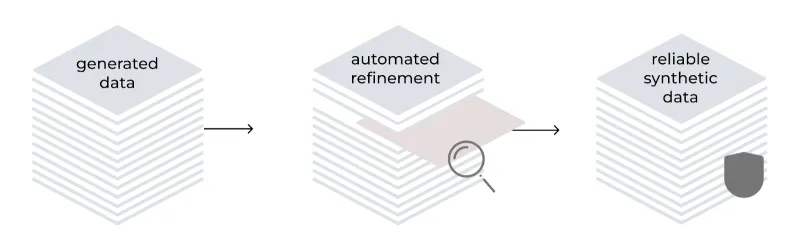
Perfezionamento automatizzato
Il metodo LAB incorpora un processo di perfezionamento automatizzato per migliorare la qualità e l'affidabilità dei dati di addestramento generati in modo sintetico. Basato su una tassonomia gerarchica, utilizza il modello sia come generatore che come valutatore. Il processo include la generazione di istruzioni, il filtraggio dei contenuti, la generazione di risposte e la valutazione delle coppie, utilizzando un sistema di valutazione a 3 punti. Per le attività basate sulle conoscenze, i contenuti generati si basano su documenti sorgente affidabili, che risolvono potenziali imprecisioni in domini specializzati.
Framework di ottimizzazione multifase
InstructLab implementa un processo di addestramento in più fasi per migliorare in modo incrementale le prestazioni del modello. Questo approccio graduale aiuta a mantenere la stabilità dell'addestramento, mentre un buffer di riproduzione dei dati impedisce l'oblio catastrofico, consentendo al modello di apprendere e migliorare continuamente. I dati sintetici generati vengono utilizzati in un processo di ottimizzazione in due fasi.
- La prima è l’ottimizzazione delle conoscenze: integra nuove informazioni fattuali, suddivise in addestramento su risposte brevi, su risposte lunghe e competenze di base.
- La seconda fase consiste nell’ottimizzazione delle competenze: migliora la capacità del modello di applicare le conoscenze a varie attività e contesti, concentrandosi sulle capacità di composizione.
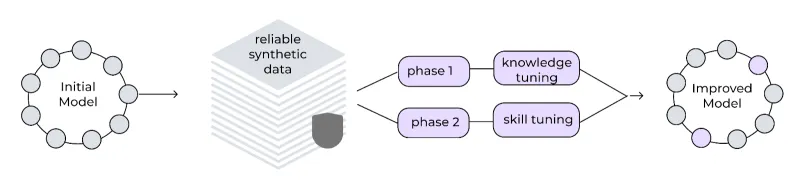
Il framework utilizza velocità di apprendimento ridotte, periodi di preparazione estesi e batch di grandi dimensioni, efficaci per garantire la stabilità.
Ciclo di miglioramento iterativo
Il processo di generazione dei dati sintetici è progettato per essere iterativo. Man mano che vengono apportati nuovi contributi alla tassonomia, possono essere utilizzati per generare altri dati sintetici, che migliorano ulteriormente il modello. Questo ciclo di miglioramento continuo aiuta a garantire che il modello sia sempre aggiornato e pertinente.
La rilevanza e i risultati di InstructLab
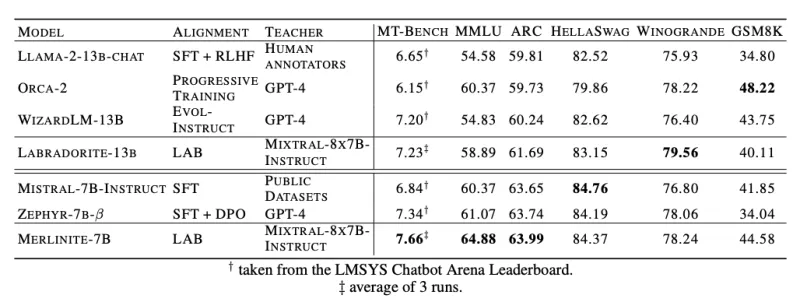
L'importanza di InstructLab risiede nella sua capacità di ottenere prestazioni all'avanguardia utilizzando modelli "insegnanti" disponibili al pubblico anziché affidarsi a modelli proprietari. Nei benchmark, la metodologia InstructLab ha mostrato risultati promettenti. Ad esempio, se applicati a Llama-2-13b (che genera Labradorite-13b) e Mistral-7B (che genera Merlinite-7B), i modelli addestrati in LAB hanno superato i modelli migliori attuali messi a punto sui rispettivi modelli base in termini di punteggi MT-Bench. Hanno anche mantenuto ottime prestazioni relativamente ad altre metriche, tra cui MMLU (test della comprensione del linguaggio multitask), ARC (valutazione delle capacità di ragionamento) e HellaSwag (valutazione dell'inferenza basata sul buon senso).
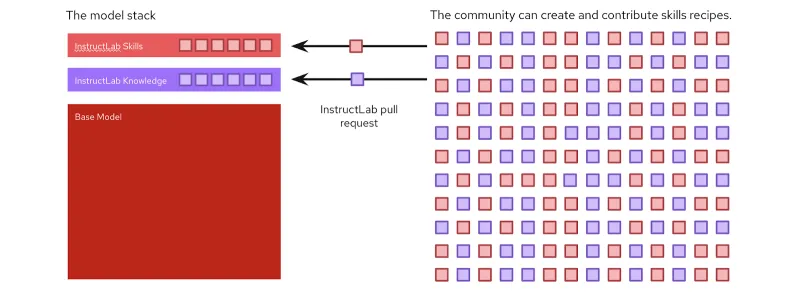
Collaborazione e accessibilità basate sulla community
Uno dei vantaggi principali di InstructLab è la sua natura open source e l'obiettivo di rendere più democratica l'IA generativa in un modo che unisca tutti nel plasmare il futuro dei modelli. L'interfaccia a riga di comando (CLI) è progettata per l'esecuzione su hardware comuni, come i laptop personali, riducendo gli ostacoli all'accesso per sviluppatori e collaboratori. Inoltre, il progetto InstructLab incoraggia il coinvolgimento della community consentendo ai membri di contribuire, offrendo nuove conoscenze o competenze, a un modello principale creato regolarmente e rilasciato su Hugging Face. Dai un'occhiata al modello più recente qui.
Il processo di generazione dei dati sintetici di InstructLab, basato sulla metodologia LAB, rappresenta un progresso significativo nel campo dell'IA generativa. Migliorando in modo efficiente gli LLM con nuove funzionalità e nuovi ambiti di conoscenza, InstructLab sta aprendo la strada a un approccio più collaborativo ed efficace allo sviluppo dell'IA. Per sapere di più sul progetto, ti consigliamo di visitare il sito instructionlab.ai o di consultare questa guida introduttiva per provare InstructLab sul tuo computer.
Sugli autori

Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.

Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
Altri risultati simili a questo
Friday Five — February 6, 2026 | Red Hat
Accelerating VM migration to Red Hat OpenShift Virtualization: Hitachi storage offload delivers faster data movement
Data Security And AI | Compiler
Data Security 101 | Compiler
Ricerca per canale

Automazione
Novità sull'automazione IT di tecnologie, team e ambienti

Intelligenza artificiale
Aggiornamenti sulle piattaforme che consentono alle aziende di eseguire carichi di lavoro IA ovunque

Hybrid cloud open source
Scopri come affrontare il futuro in modo più agile grazie al cloud ibrido

Sicurezza
Le ultime novità sulle nostre soluzioni per ridurre i rischi nelle tecnologie e negli ambienti

Edge computing
Aggiornamenti sulle piattaforme che semplificano l'operatività edge

Infrastruttura
Le ultime novità sulla piattaforma Linux aziendale leader a livello mondiale

Applicazioni
Approfondimenti sulle nostre soluzioni alle sfide applicative più difficili
Virtualizzazione
Il futuro della virtualizzazione negli ambienti aziendali per i carichi di lavoro on premise o nel cloud